

En entreprise, on reçoit rarement un PDF propre correspondant à un seul processus métier.
Dans la réalité, on reçoit plutôt un gros fichier qui mélange factures, relevés, pièces KYC, contrats, annexes, scans et justificatifs, sans ordre parfaitement prévisible. Avant même d'extraire des données, d'archiver les fichiers ou d'alimenter un système aval, il faut d'abord identifier où chaque document commence et où il se termine.
C'est ça, le vrai problème du découpage documentaire.
Workflow de découpage documentaire par IA
Pourquoi les splitters PDF classiques atteignent vite leurs limites
La plupart des outils de découpage PDF fonctionnent avec une logique figée :
- découper toutes les
npages - découper sur un code-barres ou une page séparatrice
- découper lorsqu'un mot-clé apparaît à un endroit prédéfini
Cela fonctionne dans des environnements de scan très contrôlés. En revanche, cela casse dès que :
- le fichier contient plusieurs types de documents
- le nombre de pages varie d'un document à l'autre
- les feuilles séparatrices sont absentes
- les pages sont scannées, tournées ou bruitées
- un seul PDF entrant contient des centaines voire des milliers de pages
Au final, les équipes repassent derrière le système, vérifient manuellement le fichier, renommant les documents à la main et corrigeant les erreurs lorsque des pages sont rattachées au mauvais dossier.
Ce que change un découpage documentaire par IA
Un découpage par IA ne repose pas uniquement sur des règles de pagination. Il analyse le contenu et la structure de chaque page pour répondre à des questions comme :
- Cette page appartient-elle au document précédent ou démarre-t-elle un nouveau document ?
- De quel type de document s'agit-il ?
- Quelles pages doivent rester ensemble ?
- Comment faut-il nommer le fichier de sortie ?
C'est la différence entre un simple split de pages et une vraie compréhension documentaire.
Par exemple, un workflow IA peut détecter que :
- les pages 1 à 3 correspondent à un bon de commande
- les pages 4 à 9 correspondent à une facture avec ses annexes
- les pages 10 à 18 correspondent à un relevé bancaire
- les pages 19 à 26 correspondent à un dossier de pièce d'identité
Chaque sortie peut ensuite être exportée comme un fichier distinct, avec un nom structuré, puis envoyée automatiquement dans le bon système.
Cas d'usage typiques du smart splitting
Le découpage intelligent est particulièrement utile lorsqu'un même fichier contient plusieurs documents métier :
- pièces jointes d'une boîte email regroupées dans un seul PDF
- lots de numérisation back-office
- dossiers fournisseurs
- dossiers sinistres ou contentieux avec pièces hétérogènes
- packs d'onboarding RH
- exports volumineux de data rooms ou de due diligence
Plus le fichier est volumineux et hétérogène, moins un découpage fondé sur des règles simples est fiable.
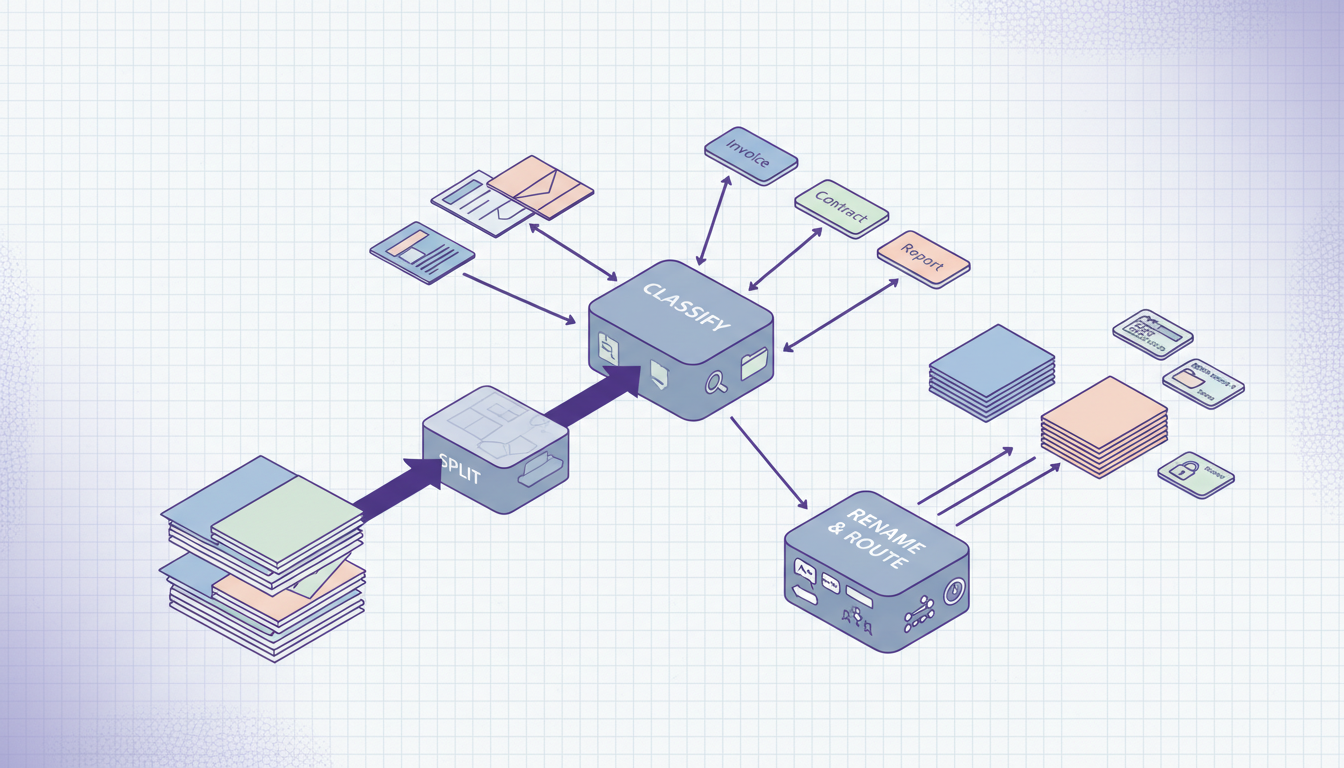
Comment Raydocs traite les PDF multi-documents
Raydocs est conçu pour des workflows d'intelligence documentaire à grande échelle, et cela inclut exactement ce besoin : séparer des PDF mixtes en documents exploitables avant ou pendant le traitement aval.
Avec Raydocs, vous pouvez mettre en place des workflows qui :
- ingèrent de très gros PDF ou des lots de PDF
- détectent si un fichier contient plusieurs documents distincts
- identifient les frontières entre documents
- classifient chaque sous-document par type
- découpent le fichier d'origine en unités documentaires propres
- renomment chaque sortie selon vos règles métier
- routent chaque document vers l'extraction, la revue, le stockage ou un système externe
Autrement dit, vous n'avez pas à choisir entre découpage et extraction. Le split peut faire partie du même pipeline documentaire.

Workflow documentaire
Transformez vos PDF mixtes en flux documentaires structurés
Configurez un pipeline Raydocs capable de détecter les frontières, classer les sous-documents, renommer les sorties et lancer l'extraction adaptée à chaque type.
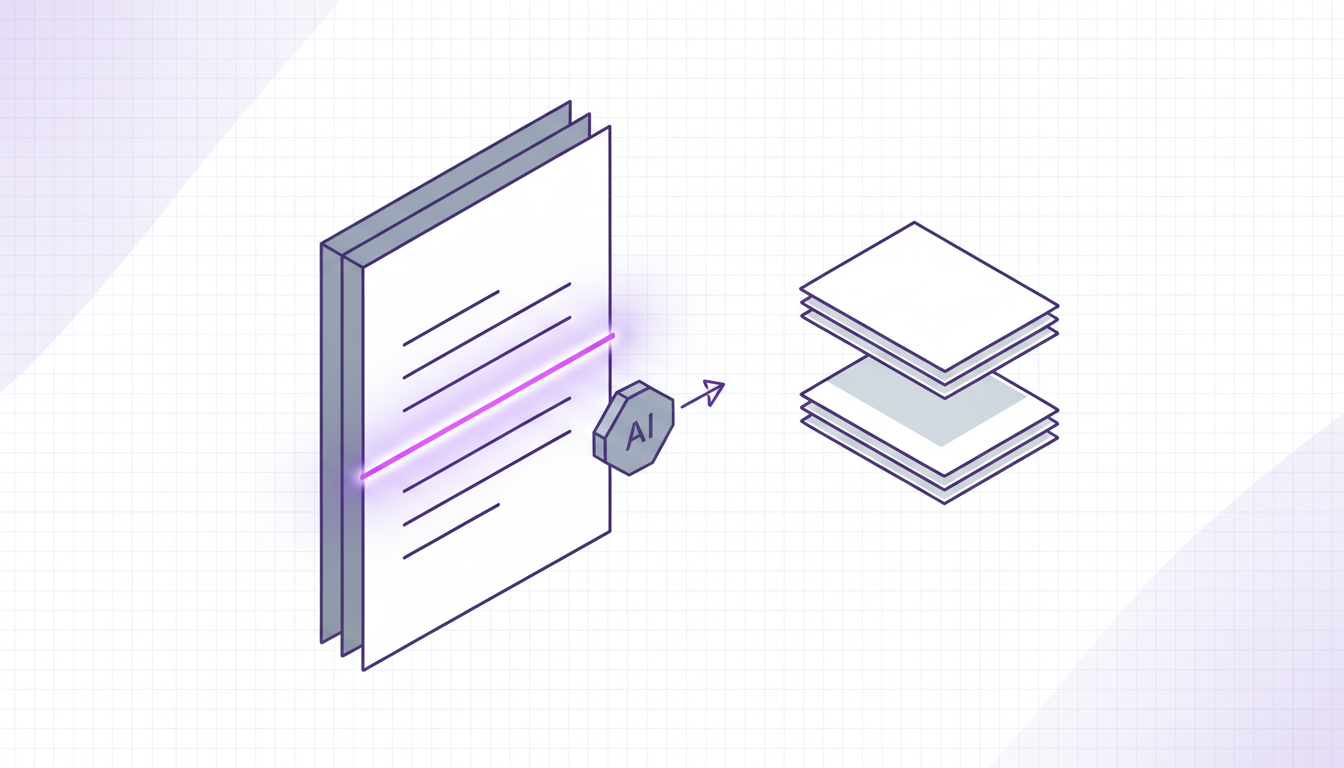
Une détection des frontières basée sur le sens, pas sur le nombre de pages
Raydocs s'appuie sur une analyse documentaire par IA pour comprendre le contenu, la mise en page et la structure visuelle des pages. C'est essentiel, car une rupture documentaire est souvent sémantique :
- une nouvelle facture démarre avec un nouvel en-tête fournisseur
- un nouveau contrat commence avec un nouveau bloc titre et de nouvelles parties
- une nouvelle pièce d'identité démarre quand le format de page et les champs changent complètement
- une annexe doit rester rattachée au document principal précédent
En pratique, le système peut donc distinguer une simple page de continuation d'un véritable début de document.
Ce point est critique pour les PDF mixtes où le nombre de pages varie et où les modèles ne sont pas uniformes.
Détecter plusieurs types de documents dans un seul PDF
Un gros PDF combiné n'est pas seulement un problème de découpage. C'est aussi un problème de classification.
Raydocs peut déterminer si un même fichier source contient plusieurs familles documentaires, puis les traiter différemment. Par exemple :
- les factures peuvent partir vers un workflow de comptabilité fournisseurs
- les contrats peuvent être routés vers une revue juridique
- les relevés bancaires peuvent être normalisés pour l'analyse financière
- les pièces d'identité peuvent alimenter un contrôle KYC
On évite ainsi de traiter tout le PDF comme s'il s'agissait d'un seul document.
Renommage automatique des fichiers générés
Le découpage n'est qu'une partie du travail opérationnel. Dans la plupart des cas, les équipes ont aussi besoin de noms de fichiers normalisés.
Raydocs peut appliquer des règles de renommage à partir du contenu détecté, par exemple :
facture-acme-2026-03-14.pdfreleve-bnp-mars-2026.pdfcontrat-travail-jane-doe.pdf
Ces noms peuvent être construits à partir de métadonnées extraites comme le fournisseur, le titulaire, la date du document, l'entreprise ou l'identifiant de dossier.
Cela facilite ensuite le stockage, la recherche et le rapprochement.
Traiter de très gros documents
De nombreux outils fonctionnent sur de petits exemples, mais deviennent fragiles dès que les fichiers sont volumineux ou hétérogènes.
Raydocs est pensé pour des opérations documentaires à fort volume :
- PDF volumineux
- nombreux documents au sein d'un même fichier
- ingestion par lot
- extraction et export aval via API
Ce point compte lorsque le découpage n'est pas une tâche isolée, mais une étape au sein d'un workflow de production.
Pourquoi ce découpage améliore aussi l'extraction
Si vous essayez d'extraire des données d'un PDF mixte avant de séparer les documents sous-jacents, la qualité se dégrade rapidement :
- des champs peuvent être attribués à la mauvaise entité
- des montants peuvent être lus dans la mauvaise section
- les résultats deviennent plus difficiles à auditer
Séparer les documents en amont crée des unités plus propres pour la classification et l'extraction. Cela améliore aussi la traçabilité, car chaque résultat est rattaché au bon document source et aux bonnes pages.
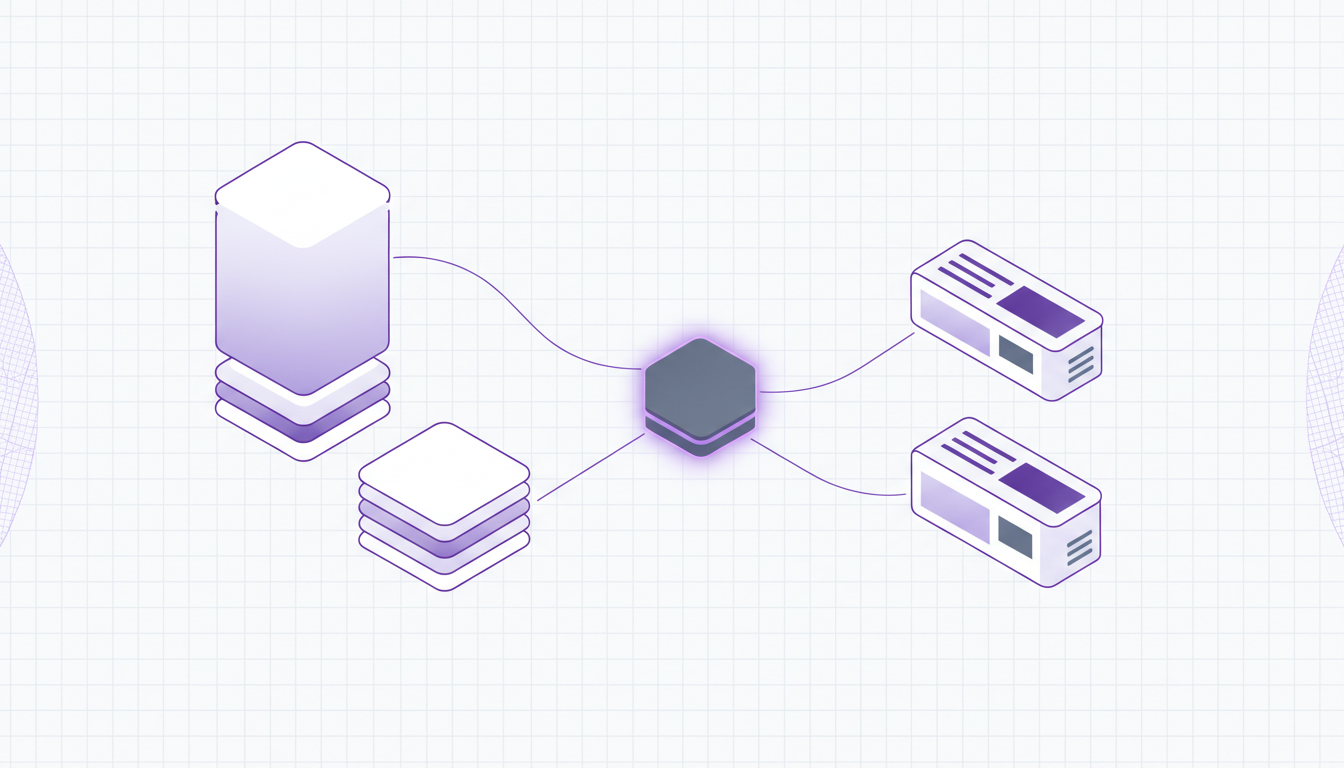
Exemple de workflow avec Raydocs
Un déploiement typique ressemble à ceci :
- Une équipe dépose ou transfère un gros PDF.
- Raydocs analyse le fichier page par page.
- Le système détecte les frontières documentaires et les types de documents.
- Chaque document détecté est isolé comme un fichier logique distinct.
- Raydocs renomme la sortie selon vos règles.
- Les workflows d'extraction pertinents s'exécutent par type de document.
- Les données structurées sont exportées vers vos systèmes cibles.
On supprime ainsi le pré-tri manuel tout en gardant une chaîne de traitement auditée.
Quand préférer l'IA aux pages séparatrices
Les pages séparatrices restent utiles dans des chaînes de numérisation très contrôlées. Mais le découpage par IA devient généralement préférable quand :
- vous ne maîtrisez pas la façon dont les fichiers sont produits
- les fichiers arrivent par email, portail ou tiers
- les formats documentaires évoluent souvent
- plusieurs types de documents sont mélangés
- vous voulez réunir découpage, classification, renommage et extraction dans un seul système
Raydocs pour le découpage documentaire par IA
Si votre équipe a besoin de plus qu'un simple cutter PDF, Raydocs peut être configuré pour prendre en charge l'ensemble du workflow :
- détecter plusieurs documents dans un seul PDF
- découper automatiquement les fichiers mixtes
- classifier chaque document résultant
- renommer les sorties avec vos métadonnées métier
- lancer l'extraction adaptée à chaque type documentaire
- exporter les résultats vers vos systèmes et APIs existants
La différence opérationnelle est là : on ne se contente pas de couper des pages, on comprend les documents.
Si vous voulez transformer de gros PDF hétérogènes en flux documentaires structurés et traçables, Raydocs est conçu pour cela.
